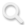转载自:上海创智学院
引言
顶尖科学家与普通研究者之间的差距,往往不在于谁更会跑实验,而在于一种难以言喻的“科研品味”——一种精准判断什么研究值得做、什么方向能出大成果的前瞻力。
本研究发现,AI 也能学到科研品味!
利用大规模科研社区的反馈信号进行训练,模型不仅能判断研究的潜在影响力,还能提出更有影响力的科研思路,让 AI 向人类级别科学家迈出关键一步。
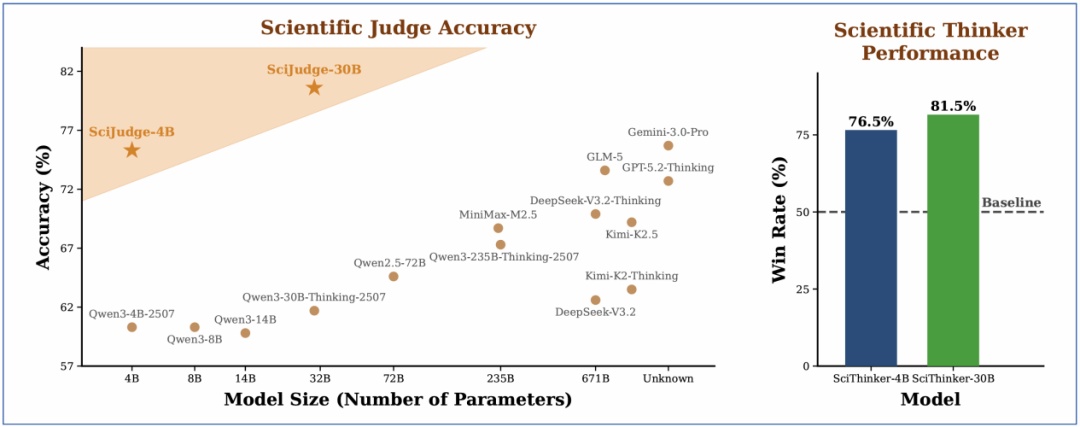
图1:研究训练的Scientific Judge科研判断力超过SOTA模型(左图);Scientific Thinker训练后,科研想法构思能力有了大幅提升(右图)。

科研品味:AI 科学家缺失的重要能力
科研品味并不是主观任性的。正如哲学家休谟所言,品味的标准建立在“合格评判者的共同裁决”之上;康德也认为品味包含着某种广泛的共识。在科学研究中,这种共同裁决本质上是学术共同体长期互动的结果:被广泛复用、持续延伸的研究,因契合了科研共同体的集体判断而产生了高影响力。基于此,研究将科研品味定义为:判断和构思高影响力研究想法的能力。
目前,AI 科学家虽能检索文献、编写代码、运行实验,却恰恰在判断 “什么值得研究” 以及 “构思高影响力研究”方面有明显不足。为填补这一空白,本研究设计了科研判断与科研构思这两个任务:
科研判断(Scientific Judgement):给两篇论文(标题+摘要),通过推理判断哪篇有更高的影响力(图2)。

图2:Scientific Judgement 任务示例,对应研究训练的 Scientific Judge 模型
科研构思(Scientific Ideation):给一篇论文(标题+摘要),构思一个高潜力的后续科研思路,输出标题+摘要(图3)。

图3:Scientific Ideation任务示例,对应研究训练的Scientific Thinker模型
RLCF 范式:基于社区反馈的强化学习
科研构思并无标准答案,RLVR 不适用;而 RLHF 也存在局限:人工标注昂贵,且难以体现社区层面的集体偏好。
研究因此提出了新范式:Reinforcement Learning from Community Feedback(RLCF)。核心思想在于,有影响力的工作被广泛复用、跟进与延伸,形成海量科研社区的反馈信号(如引用数),天然可以用于训练。
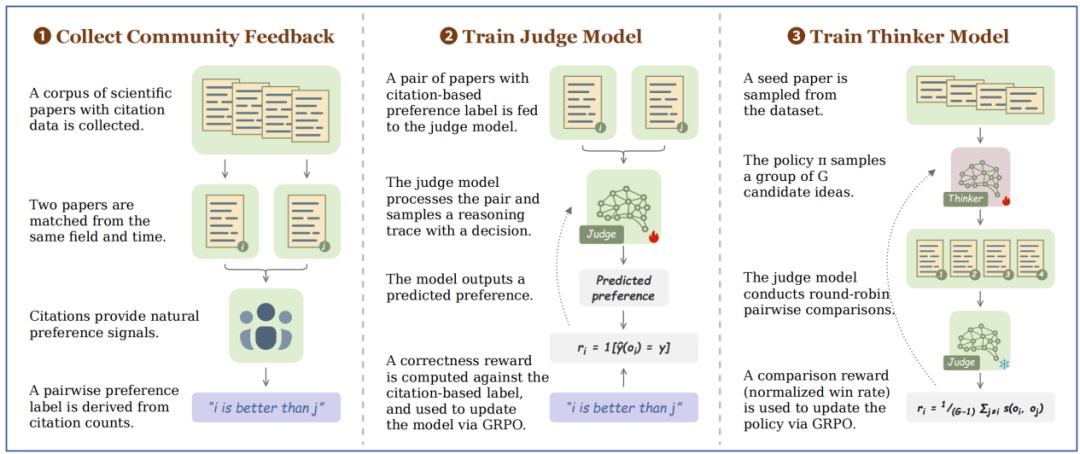
图4:RLCF 范式的三个步骤。(1) 收集社区反馈(如引用数);(2) GRPO 训练 Judge;(3) GRPO 训练 Thinker,用 Judge 对一组想法排序从而确定奖励。
RLCF 分为三步(图4):
Step 1:收集社区反馈,构建偏好对:对于同领域、同年份论文,有明显引用差异的两篇论文配对。
Step 2:训练 Judge:学会正确判断两篇论文哪篇更有影响力。
Step 3:训练 Thinker:基于所给论文构思后续研究思路,用 Judge 作为奖励模型进行优化。
Scientific Judge:学会判断什么研究更有影响力
研究构建了 SciJudgeBench 这一大规模数据集 :70万对 arXiv 论文(领域&年份严格匹配,引用数差异显著),为 Judge 的训练与评测提供坚实基础。
训练后的 Scientific Judge 表现出三个显著特点:
扩展效应明显
数据量越大、模型参数越多,性能越强(如图5),证明了学习可扩展。
图5:Scientific Judge 训练的 Scaling Effect,两种颜色对应 4B 和 30B 的模型
超越SOTA
30B 的 Judge 超越 Gemini 3 Pro、GLM-5 等顶尖模型,如表1。
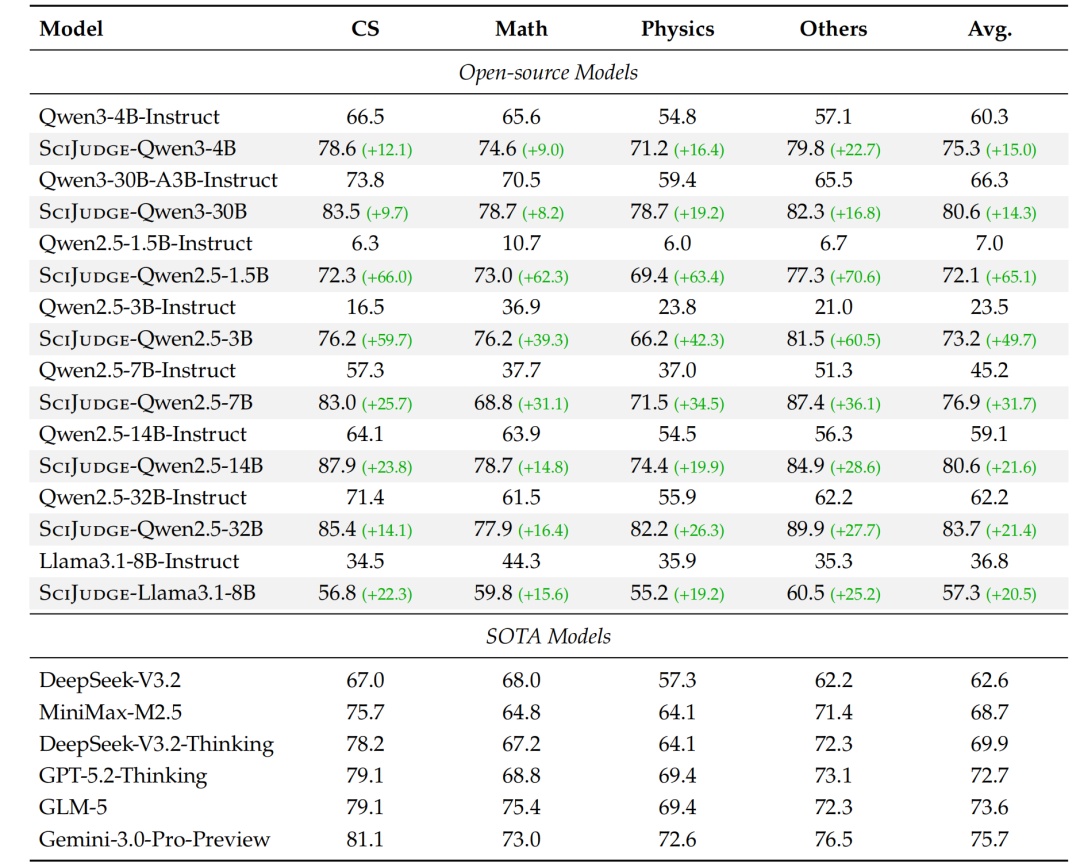
表1:域内评测结果,测试和训练数据所处时间一致,均为 2024 年及之前
三重域外泛化(图6)
时间域外泛化:准确判断 2025 年(训练数据之后)的论文。
不同领域泛化:只训练 CS 领域论文,能泛化到数学、物理、生物等领域。
同行审稿标准:仅基于引用数训练后,比较 ICLR 得分也更加准确。
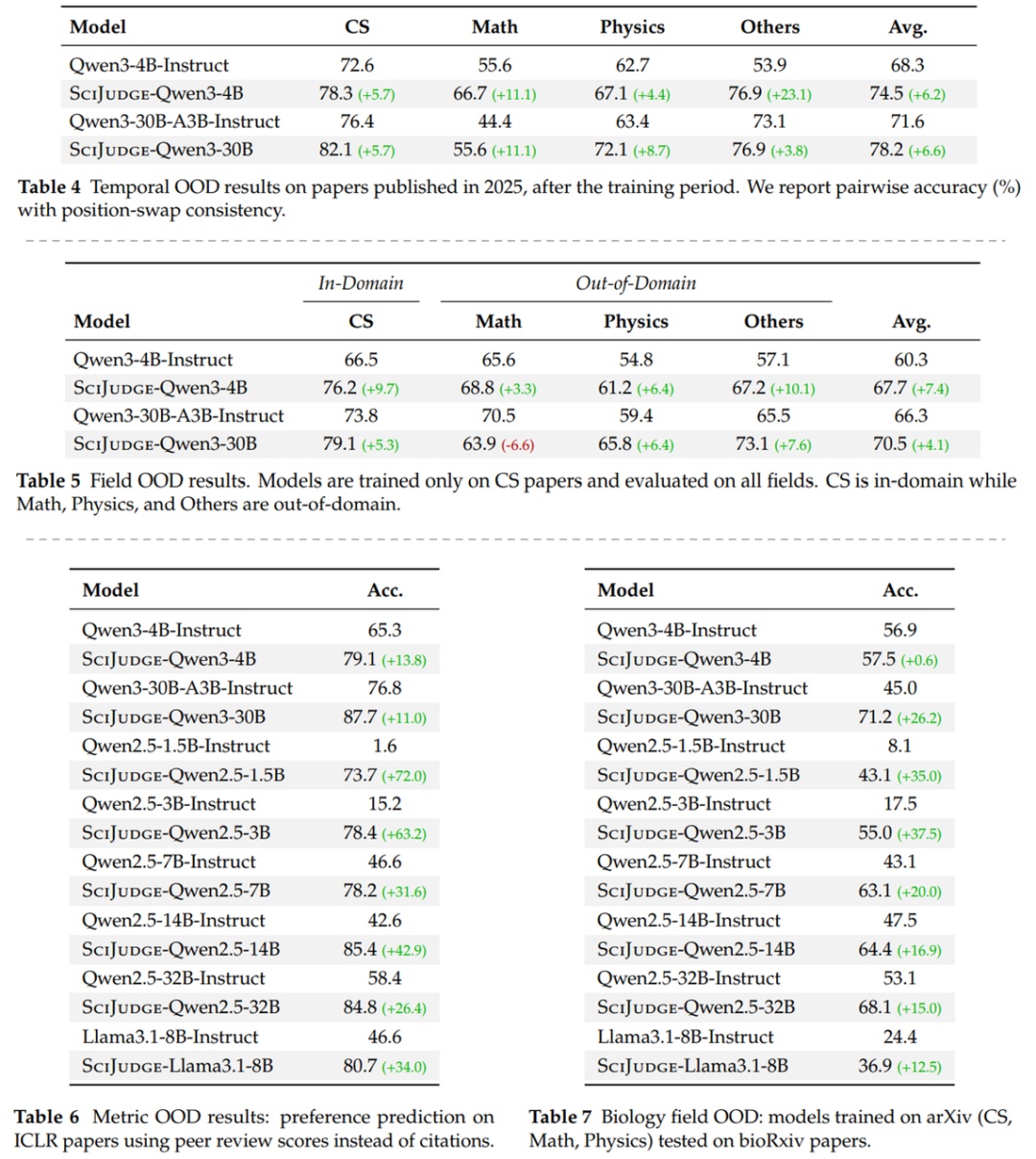
图6:三方面域外测试评测结果。上方:时间域外;中间:领域域外;下方:指标域外(ICLR 得分比较)。
由此可知,Judge 模型并不只是 “记忆”,而是学习到了一种通用的、可迁移的科研判断力,不受时间、具体领域或特定指标的限制。
Scientific Thinker:学会构思更有影响力的科研想法
科研构思能力实现显著提升。30B 和 4B 的 Thinker 模型构思的想法,对基座模型的胜率达到 75~80%,并泛化到“未来”论文(晚于训练数据)的研究主题上(图7上方)。
Scientific Judge 是更好的生成式奖励模型。以 Judge 作为奖励模型训练得到的 Thinker,表现远超使用基线奖励模型的版本(图7的上下对比)。
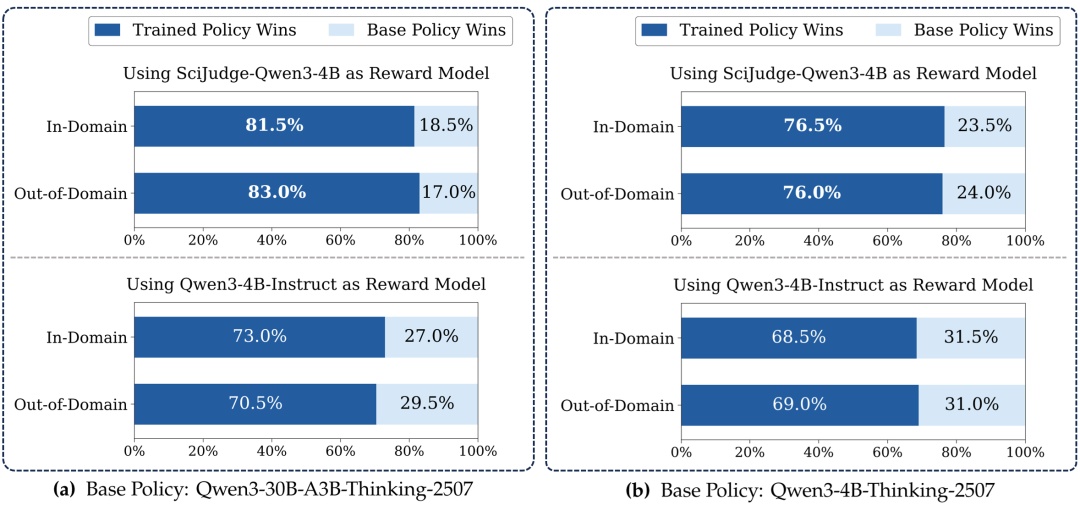
图7:Scientific Thinker相对训前模型的胜率。左、右分别是 30B 和 4B 的策略模型。第一行使用 Scientific Judge 作为奖励模型,第二行使用基线奖励模型。“Out-of-Domain” 指测试数据所处时间晚于训练数据。
与 SOTA 模型相媲美。30B 的 Thinker 与三个顶尖模型进行科研想法对决,也有出色表现(表2)。

表2:30B 的 Scientific Thinker 对战三个 SOTA 模型的胜率
至此,科研品味学习完美闭环:Scientific Judge 精准判断,并促成 Scientific Thinker 优秀构思。
总结
“科研品味” 并非人类科学家的专属天赋。通过从大量科研社区的反馈中学习,AI 也能学到科研品味,“从不可能到可能”,迈向人类水平的 AI 科学家。
欢迎转发,但请注明出处“上海经信委”
觉得不错请点赞!